Table of Links
-
Discussion and Broader Impact, Acknowledgements, and References
D. Differences with Glaze Finetuning
H. Existing Style Mimicry Protections
K User Study
This user study was approved by our institution’s IRB.
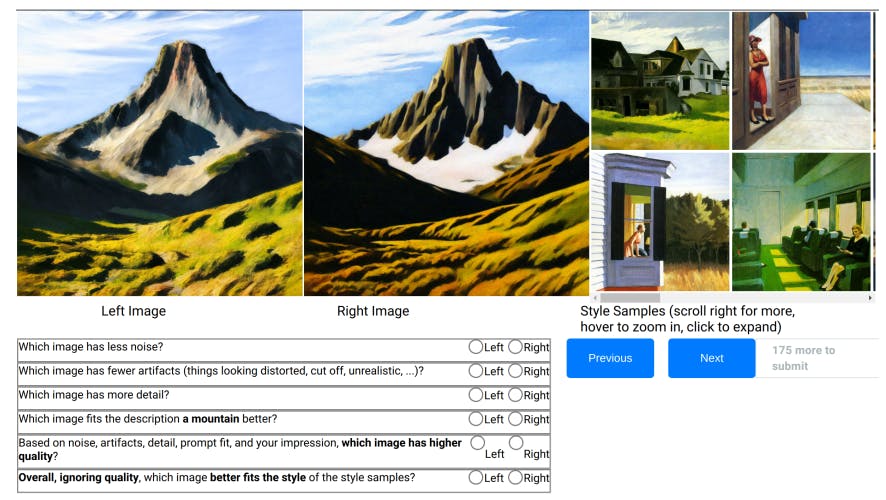
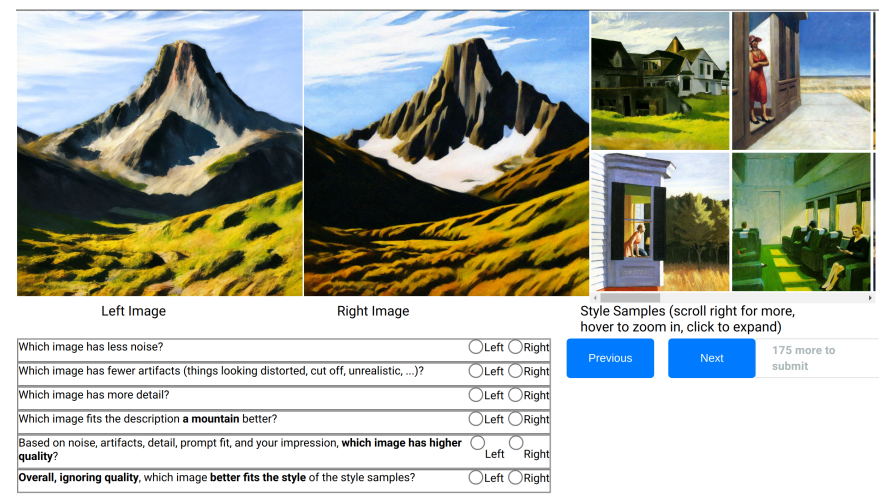
Design. Our user study asks annotators to compare outputs from one robust mimicry method against a baseline where images are generated from a model trained on the original art without protections—for a fixed set of prompts P.
We present participants with both generations and a gallery with original art in the target style. We ask participants to decide which image is better in terms of style and quality, separately. For this, we ask them two different questions:
-
Based on noise, artifacts, detail, prompt fit, and your impression, which image has higher quality?
-
Overall, ignoring quality, which image better fits the style of the style samples?
For each comparison, we collect data from 5 users. We randomize several aspects of our study to minimize user bias. We randomly select the order of robust mimicry and baseline generations. Second, we randomly shuffle the order of all image comparisons to prevent all images from the same mimicry method to appear consecutively. Finally, we also randomly sample the seeds that models use to generate images to prevent repeating the same baseline image across different comparisons.
Differences with Glaze’s user study. Our study does not exactly replicate the design of Glaze’s user study for two reasons. First, the Glaze study provided annotators with four AI-generated images and four original images, asking if the generated images successfully mimicked the original artwork. This evaluation fails to account for the commonly encountered scenario where current models are incapable of reliably mimicking an artist’s style even from unprotected art. Second, we believe the relative assessment recorded in our study (“Which of these two mimicry attempts is more successful?”) is easier for humans than the absolute assessment used in the Glaze study (“Is this mimicry attempt successful”).
Prompts. We curate a small dataset of 10 prompts P. We design the prompts to satisfy two criteria:
-
The prompts should cover diverse motifs with varying complexity. This ensures that we can detect if a scenario compromised the prompt-following capabilities of a style mimicry model.
-
The prompts should only include prompts for which our finetuning base model M, SD 2.1, can successfully generate a matching image. This reduces the impact of potential human bias against common defects of SD 2.1.
To satisfy criterion 1 and increase variety, we instruct ChatGPT to generate prompt suggestions for four different categories:
-
Simple prompts with template “a {subject}”.
-
Two-entity prompts with template “a {subject} {ditransitive verb} a {object}”.
-
Entity-attribute prompts with template “a {adjective} {subject}”.
-
Entity-scene prompts with template “a {subject} in a {scene}”.
The chat we used to generate our prompts can be accessed at https://chatgpt.com/share/ ea3d1290-f137-4131-baca-2fa1c92b3859. To satisfy criterion 2, we generate images with SD 2.1 on prompts suggested by ChatGPT and manually filter out prompts with defect generations (e.g. a horse with 6 legs). We populate the final set of prompts P with 4 simple prompts, 2 two-entity prompts, 2 entity-attribute prompts, and 2 entity-scene prompts (see Figure 29).

Quality control. We first run a pilot study where we directly ask users to answer the previous questions about style and quality. This study resulted in very low-quality responses that are barely better than random choice. We enhanced the study to introduce several quality control measures to improve response quality and filter out low-quality annotations:
-
We limit our study to desktop users so that images are sufficiently large to perceive artifacts introduced by protections.
-
We precede the questions we use for our study with four dummy questions about the noise, artifacts, detail, and prompt matching of the images. The dummy questions force annotators to pay attention and gather information useful to answer the target questions.
-
We precede our study with a training session that shows for question 1, 2, and each of the four dummy questions an image pair with a clear, objective answer. The training session helps users to understand the study questions. We introduced this stage after gathering valuable feedback for annotators.
-
We add control comparisons to detect annotators who did not understand the tasks or were answering randomly. We generated several images from the baseline model trained on the original art. For each of these images, we created two ablations. For question 1 (quality), we include Gaussian noise to degrade its quality but preserve the same information. For question 2 (style), we apply Img2Img to remove the artist style and map the image back to photorealism using the prompt “high quality photo, award winning”. We randomly include control comparisons between the original generations and these ablations, and we only accept labels from users who answered correctly at least 80% of the control questions.
Execution. We execute our study on Amazon Mechanical Turk (MTurk). We design and evaluate an MTurk Human Intelligence Task (HIT) for each artist A ∈ A, shown in Figure 30. Each HIT includes image pair comparisons for a single artist A under all scenarios S ∈ M, as well 10 quality control image pairs, 10 style control image pairs, and 6 training image pairs. We generate an image pair for each of the 10 prompts and each of 15 scenarios, for a total of 10 · 15 + 10 + 10 + 6 = 176 image pairs per HIT. We estimate study participants to spend 5 minutes on the training image pairs and 30 seconds per remaining image pair, so 90 minutes in total. We compensate study participants at a rate of $16/hour, so $24 per HIT.
K.1 Style Mimicry Setup Validation
We execute an additional user study to validate that our style mimicry setup in Appendix G successfully mimics style from unprotected images.

For each prompt P ∈ P and artist A ∈ A, our validation study uses the baseline model trained on uprotected art to generate one image. Inspired by the evaluation by Glaze (Shan et al., 2023a), we ask participants to evaluate the style mimicry success by answering the question:
How successfully does the style of the image mimic the style of the style samples? Ignore the content and only focus on the style.

-
Not successful at al
-
Not very successful
-
Somewhat successful
-
Successful
-
Very successful
We also execute the style mimicry validation study on MTurk. We design and evaluate a single HIT for all questions, shown in Figure 33. We estimate study participants to spend 15 seconds on each question, and to spend 1 minute to familiarize themselves with a new style, so 35 minutes in total. We compensate study participants at a rate of $18/hour, so $10.50 per HIT
We find that style mimicry is successful in over 70% of the comparisons. Results are detailed in Figure 31.


Authors:
(1) Robert Honig, ETH Zurich ([email protected]);
(2) Javier Rando, ETH Zurich ([email protected]);
(3) Nicholas Carlini, Google DeepMind;
(4) Florian Tramer, ETH Zurich ([email protected]).
This paper is