
Table of Links
-
Discussion and Broader Impact, Acknowledgements, and References
D. Differences with Glaze Finetuning
H. Existing Style Mimicry Protections
I Robust Mimicry Methods
This section details the robust mimicry methods we use in our work. These methods are not aimed at maximizing performance. Instead, they demonstrate how various ”off-the-shelf” and low-effort techniques can significantly weaken style mimicry protections.

I.1 DiffPure

If the text-to-image model M supports unconditional image generation, then we can use model M for the reverse diffusion process. For example, Stable Diffusion (Rombach et al., 2022) generates images unconditionally when the prompt P equals the empty string. Under these conditions, Img2Img is equivalent to DiffPure. Therefore, in the context of defenses for style mimicry, we refer to Img2Img applied with an empty prompt P as unconditional DiffPure, and to Img2Img applied with a non-empty prompt P as conditional DiffPure.
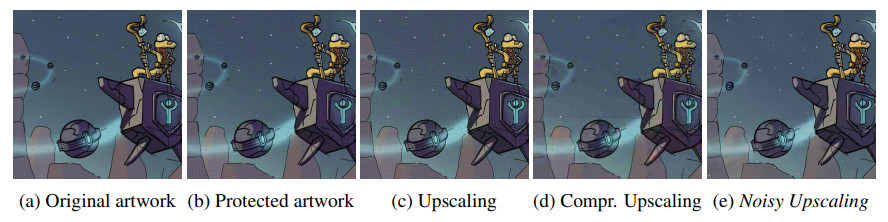
I.2 Noisy Upscaling
Upscaling increases the resolution of an image by predicting new pixels that enhance the level of detail. Upscaling images can purify adversarially perturbed images (Mustafa et al., 2019). However, we discover that applying upscaling directly on protected images fails to remove the perturbations.

Second, we note that upscaling has shown success against adversarial perturbations for classifiers (Mustafa et al., 2019), but not against adversarial perturbations for generative models (Liang et al., 2023; Shan et al., 2023a).
I.3 IMPRESS++
We enhance the IMPRESS algorithm (Cao et al., 2024). We change the loss of the reverse encoding optimization from patch similarity to l∞ and include two additional steps: negative prompting and post-processing. All in all, IMPRESS++ first preprocesses protected images with Gaussian noise and reverse encoder optimization, then samples using negative prompting and finally post-processes the generated images with DiffPure to remove noise.



Figure 27 illustrates the improvements introduced by each additional step.

Authors:
(1) Robert Honig, ETH Zurich ([email protected]);
(2) Javier Rando, ETH Zurich ([email protected]);
(3) Nicholas Carlini, Google DeepMind;
(4) Florian Tramer, ETH Zurich ([email protected]).
This paper is