
Table of Links
-
Discussion and Broader Impact, Acknowledgements, and References
D. Differences with Glaze Finetuning
H. Existing Style Mimicry Protections
J Experimental Setup
This section describes our general experimental setup and specifies the settings and hyperparameters of the methods we use. When possible, we use default values from the machine learning literature. For implementation details see our official repository: https://github.com/ethz-spylab/ robust-style-mimicry
J.1 Style Mimicry Experimental Details
As described in Section 3, our threat model considers style mimicry with a latent diffusion text-toimage model M that is finetuned on a set of images X in a style S. This section specifies our choices for model M, images X, style S, the hyperparameters for finetuning M, and the hyperparameters for generating images with the finetuned model. Where possible, we try to replicate the style mimicry setup used by Shan et al. to evaluate Glaze, and highlight any differences.
Model We use Stable Diffusion version 2.1 (Stability AI, 2022), the same model used to optimize the protections we evaluate (Shan et al., 2023a; Liang et al., 2023; Van Le et al., 2023).


J.2 Protections Experimental Details

Next, we describe specific hyperparameters we use to reproduce each of the protections.
J.2.1 Anti-DreamBooth

J.2.2 Mistϕ
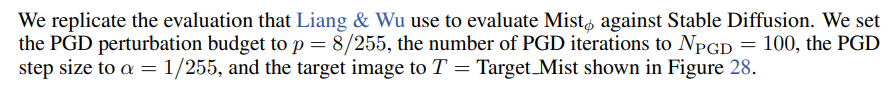
J.2.3 Glaze
The Glaze authors were unable to share a codebase upon request. We thus use their publicly released Windows application binary. We use the latest available version of Glaze, v1.1.1. We set Intensity

to High and Render Quality to Slowest, to obtain the strongest protections. Appendix E includes qualitative results on an updated version released after we concluded our user study.
J.3 Robust Mimicry Methods Experimental Details
J.3.1 Gaussian noising
We manually tune the Gaussian noising strength to σ2 = 0.05.
J.3.2 DiffPure
We use conditional DiffPure with the best-performing publicly available image generation diffusion model, Stable Diffusion XL 1.0 (SDXL) (Podell et al., 2023). We implement conditional DiffPure using the HuggingFace AutoPipelineForImage2Image pipeline. We use classifier-free guidance scale guidance scale = 7.5 with prompt P = Cx for image x. We manually tune the number of diffusion timesteps t via the strength pipeline argument to strength = 0.2.
J.3.3 IMPRESS++

Authors:
(1) Robert Honig, ETH Zurich ([email protected]);
(2) Javier Rando, ETH Zurich ([email protected]);
(3) Nicholas Carlini, Google DeepMind;
(4) Florian Tramer, ETH Zurich ([email protected]).
This paper is
[8] www.artstation.com
[9] @nulevoy is the first ArtStation artist that we experimented with. In our experiments, we found “nulevoy” a suitable choice for the special word w∗ and use it for all artists. We check that all of nulevoy’s images are published after the release date of LAION-5B to ensure that SD 2.1 has no prior knowledge about nulevoy’s style.